

What is write-back?
Write-back in this context refers to manipulating data in a database from Looker web UI, without having to code. Primarily designed for business users, common use cases include –
- Adding comments to dashboards.
- Users managing tables (pricing, etc.).
- Audit applications.
- Feedback forms.
How can this be accomplished with Looker?
By using Actions by Looker.
What should you be familiar with?
- Python (or NodeJS)
- LookML
What should you have?
- Permissions to manage Google Cloud Functions in your GCP.
- Looker Dev Access
Have them all? Let’s get started.
Example use case:
Consider the following table:
actions_ad_data
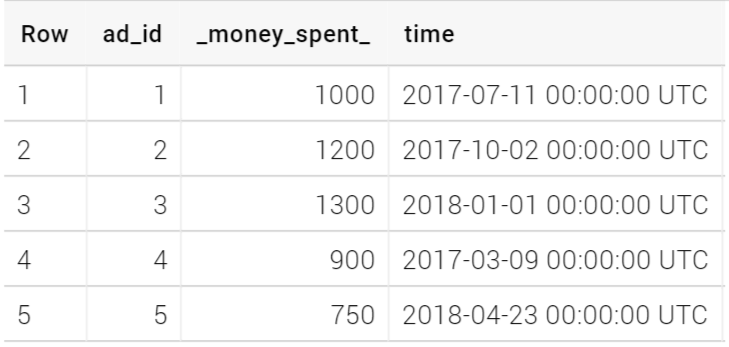
Users should be able to update the information/add comments in this table directly from Looker dashboards. This article walks you through the process of achieving that functionality.
As a part of that, to catch all the entered comments, a new table has to be created on the database, similar to this one:
actions_comments

And on Looker, create a view on the comments table, and join it with the initial ad_data explore, as follows:
view: actions_comments {
sql_table_name: !@#$%^&*.actions_comments ;;
dimension: ad_id {
type: number
sql: ${TABLE}.ad_id ;;
}
dimension: comment {
type: string
sql: ${TABLE}.comment ;;
}
dimension: p_key {
type: string
primary_key: yes
sql: ${ad_id}|| '' || ${time_raw} ;;
}
dimension_group: time {
type: time
timeframes: [
raw,
time,
date,
week,
month,
quarter,
year
]
sql: ${TABLE}.time ;;
}
dimension: u_name {
type: string
sql: ${TABLE}.u_name ;;
}
measure: count {
type: count
drill_fields: [u_name]
}
}connection: "!@#$%^&*"
include: "*.view.lkml"
explore: actions_ad_data {
label: "Ad Data"
description: "Created just to try Data Actions."
join: actions_comments {
sql_on: ${actions_ad_data_dt.ad_id} = ${actions_comments.ad_id} ;;
relationship: one_to_many
type: left_outer
}
}Before moving on with actual implementation, here is a high-level illustration of the entire writeback process using Data Actions:
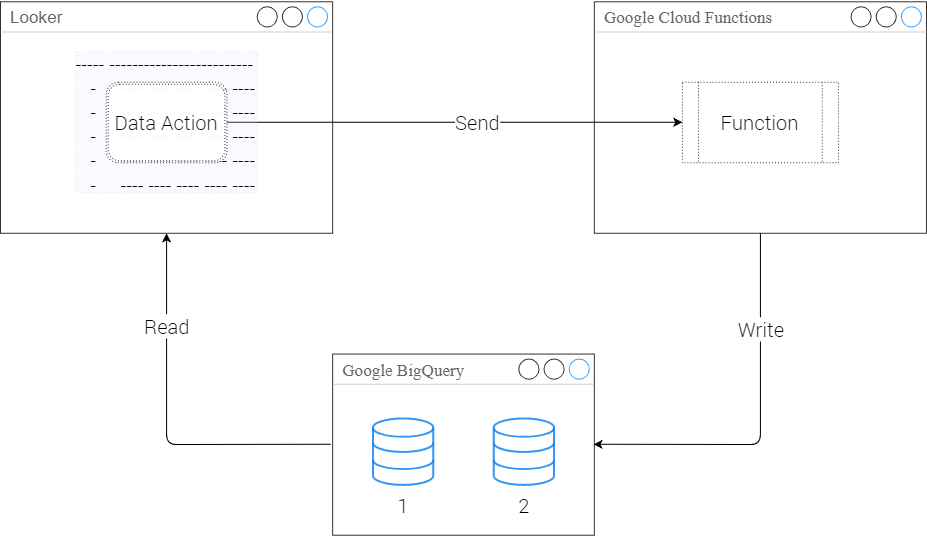 Within a Looker Action, all the parameters and forms are bundled together as a JSON. And when a cloud function is triggered by that action, that cloud function collects the bundled information from Looker, validates it and posts the data onto the database according to the given instructions. Make sure to give those instructions good and accurate.
Within a Looker Action, all the parameters and forms are bundled together as a JSON. And when a cloud function is triggered by that action, that cloud function collects the bundled information from Looker, validates it and posts the data onto the database according to the given instructions. Make sure to give those instructions good and accurate.
Now, assuming that all of the important visualizations will be including the actions_ad_data.ad_id, two data actions were added to that dimension, as follows:
view: actions_ad_data {
sql_table_name: !@#$%^&*.actions_ad_data ;;
.
.
.
dimension: ad_id {
type: number
primary_key: yes
sql: ${TABLE}.ad_id ;;
action: {
label: "Update Money Spent"
url: "https://!@#$%^&*.cloudfunctions.net/changeamount_actions"
param: {
name:"id"
value: "{{value}}"
}
form_param: {
name: "changeamount"
type: string
label: "Amount"
description: "Enter new amount above."
required: yes
}
}
action: {
label: "Add comment"
url: "https://!@#$%^&*.cloudfunctions.net/changeamount_comments"
param: {
name:"id"
value: "{{value}}"
}
user_attribute_param: {
user_attribute: user_attribute_name
name: "username"
}
form_param: {
name: "comment"
type: textarea
label: "Enter the comment"
required: yes
}
}
}
.
.
.
}The two actions are “Update Money Spent” and “Add comment”. They are almost the same but understand that the target URLs are different, targeting a cloud function relevant to the action. Here are the cloud functions that are up and running on the Google Cloud:
 Here is “changeamount_actions” function configuration:
Here is “changeamount_actions” function configuration:
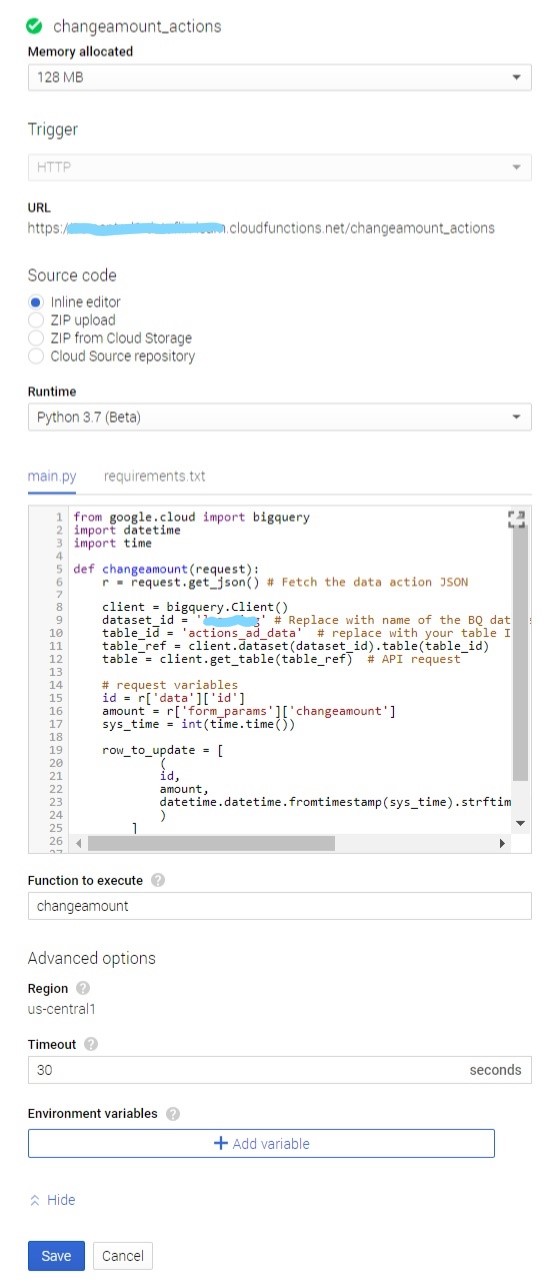
Note: Don’t forget to mention ‘google-cloud-bigquery==1.5.0’ in requirements.txt of each cloud functions. Also, this function can be done using NodeJS as well.
And it’s source code:
from google.cloud import bigquery # DO NOT FORGET THIS
import datetime
import time
def changeamount(request):
r = request.get_json() # Fetch the data action JSON
client = bigquery.Client()
dataset_id = '!@#$%^&*' # Replace with name of your BQ dataset
table_id = 'actions_ad_data' # replace with your table ID
table_ref = client.dataset(dataset_id).table(table_id)
table = client.get_table(table_ref)
# getting the data
id = r['data']['id']
amount = r['form_params']['changeamount']
sys_time = int(time.time())
row_to_update = [
(
id,
amount,
datetime.datetime.fromtimestamp(sys_time).strftime('%Y-%m-%d %H:%M:%S')
)
]
row = client.insert_rows(table, row_to_update) # API request to insert row
return '{"looker": {"success": true,"refresh_query": true}}' # return success response to Looker forcing it to refresh[/vc_column_text][vc_column_text css=”.vc_custom_1541804171616{margin-bottom: 0px !important;}”]The other Cloud Function’s configuration is similar to the first one, and so here is the source code of it:
from google.cloud import bigquery
import datetime
import time
def addcomment(request):
r = request.get_json() # Fetch the data action JSON
client = bigquery.Client()
dataset_id = 'learning' # Replace with name of the BQ dataset
table_id = 'actions_comments' # replace with your table ID
table_ref = client.dataset(dataset_id).table(table_id)
table = client.get_table(table_ref) # API request
# request variables
id = r['data']['id']
u_name = r['data']['username']
comment = r['form_params']['comment']
sys_time = int(time.time())
row_to_update = [
(
comment,
u_name,
datetime.datetime.fromtimestamp(sys_time).strftime('%Y-%m-%d %H:%M:%S'),
id
)
]
row = client.insert_rows(table, row_to_update) # API request to insert row
return '{"looker": {"success": true,"refresh_query": true}}' # return success response to LookerBreaking down the code:
Take a look at the “Update Money Spent” action declaration in actions_ad_data.
Within that action, param and form_param contain the data that might be required to be sent to the server (which in this case is the Cloud Function). Read about param and form_param in this link.
The second action is “Add comment”, which is similar to the first one, but with a new user_attribute_param, which just contains the user attributes, and in this case the full name of currently logged in user. This can also be achieved by using ‘liquid’.
Now, on the cloud function, the dataset_id and table_id onto which the data is to be written is hard-coded into specific variables. And also, the function tries to retrieve data from the JSON, store it within appropriate variables and then tries inserting all the variables together onto the table as a new row.
Here is a video of Data Actions on an example dashboard created on the example data:
Remember:
#1
BigQuery is append-only. So, new rows will be added, instead of updating existing rows. Here is one way to avoid showing duplicates on Looker:
- Make sure the table have timestamps.
- Create a PDT to retrieve the latest information of each pkey, and set a sql_trigger on the timestamp field.
#2
Do not share the Cloud Function’s URL. Anyone with the URL can write data to your BigQuery instance. Try adding some checks/validation that the request is coming from Looker.
#3
Make sure the end-user knows where the data actions are, and how they’re supposed to be used.
Other Useful links:
Joins in Looker: https://docs.looker.com/data-modeling/learning-lookml/working-with-joins
About Datagroups: https://docs.looker.com/reference/model-params/datagroup
Another example: https://discourse.looker.com/t/update-write-back-data-on-bigquery-from-looks/9408/2
This blog was developed in collaboration with Looker’s Customer Success Engineer Jesse Carah.